src.pi_controller¶
It is recommended to check SoyutNet documentation before going through this document.
Summary¶
This simulation investigates that a proportional-integral (PI) controller structure can be used to balance the work load of two TCP servers which accepts requests from a single source.
The auto-generated PT net diagram is given below.
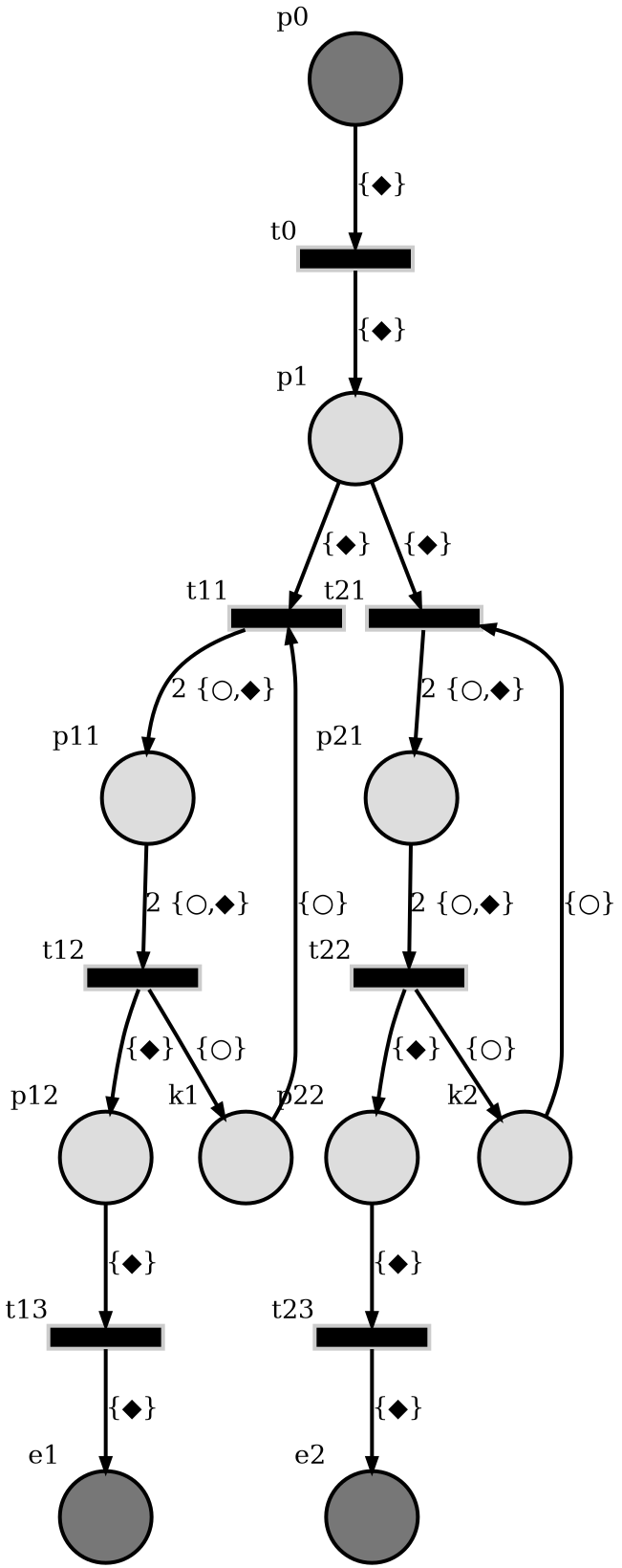
In the diagram,
\(p_0\) is producing the requests which are represented by tokens with ‘◆’ labels. The tokens are generated at a pre-determined rate.
\(e_1\) and \(e_2\) are consumers.
At \(p_1\), the graph is branching and \(p_1\) is redirecting the request to the first available branch found.
Transition \(t_{11}\) fires when \(k_1, p_1\) both have tokens. After it fires, the request at \(p_1\) is transfered to the input buffer \(p_{12}\) of consumer \(e_1\) through \(p_{11}\).
Transition \(t_{21}\) fires when \(k_2, p_1\) both have tokens. After it fires, the request at \(p_1\) is transfered to the input buffer \(p_{22}\) of consumer \(e_2\) through \(p_{21}\).
Finally, the requests are processed at consumers \(e_1\) and \(e_2\). And, each processing takes a random amount of time while the producer can generate tokens at a nearly constant rate which can be greater than average processing rate.
Control rule:
The places \(k_1\) and \(k_2\) are considered as controllers that aims to balance the work load of consumers. Because, \(t_{11}\) and \(t_{21}\) can not fire unless \(k_i\) allows. So, \(p_1\) is forced to redirect request to the enabled branch. After \(t_{i1}\) is fired, the token labeled by ‘○’ will loop back to \(k_i\) at the next step.
Goal¶
Can you design a control law that makes the number of request processed by both consumers equal?
System description¶
The simulation consists of
Producer
TCP clients at consumers
TCP servers
Conrollers
The whole implementation can be found at https://github.com/dmrokan/soyutnet-simulations/blob/main/src/pi_controller/main.py
Producer¶
The producer (\(p_0\)) is assumed to generate requests (tokens) at a constant rate and transfers to \(p_1\) which will redirect it to the first available branch.
In the simulation, the latency on the paths are negligible compared to the production
rate. However, it can be adjusted by LOOP_DELAY parameter below.
221
222 net = SoyutNet()
223 net.SLOW_MOTION = True
224 net.LOOP_DELAY = 0
225
The producer logic is defined as below.
229
230 token_id = 0
231
232 async def producer(place):
233 nonlocal token_id
234 await net.sleep(PRODUCE_DELAY)
235 token_id += 1
236 return [(L, token_id)]
237
Async function producer is called in a dedicated asyncio task loop with
the period given by PRODUCE_DELAY. The produced tokens are labeled by
integer value L (namely ‘◆’).
Consumers¶
The consumer functionality is more complex because it communicates to a TCP server and also constantly notifies the controllers \(k_1\) and \(k_2\).
241
242 sensors = [asyncio.Queue() for i in range(PROC_COUNT)]
243 consumer_stats = {}
244
245 async def consumer(place):
246 async def echo_client():
247 """Simple TCP echo client"""
248 reader, writer = await asyncio.open_connection(HOST, PORTS[index])
249 writer.write(MESSAGE)
250 await writer.drain()
251 data = await reader.read(MESSAGE_SIZE)
252 writer.close()
253 await writer.wait_closed()
254
255 nonlocal consumer_stats
256 start_time = 0
257 ident = place.ident()
258 index = int(place._name[1:]) - 1
259 """Get branch index (0 or 1)"""
260 sensor = sensors[index]
261 if ident not in consumer_stats:
262 """Initialize stats at first call of the producer."""
263 consumer_stats[ident] = {"started_at": time.time(), "count": 0}
264 """Store initial time and number of requests processed to calculate requests per second."""
265 sensor.put_nowait(1)
266 """Initial push to the controllers, otherwise they will stuck at waiting the sensor."""
267
268 label = L
269 token = place.get_token(label)
270 T = time.time()
271 if not token:
272 consumer_stats[ident]["last_at"] = time.time()
273 sensor.put_nowait(0)
274 """If there is no new token in the buffer, inform the controller."""
275 return
276
277 await echo_client()
278 """Fullfill the request."""
279
280 sensor.put_nowait(1)
281 """Inform the controller."""
282 consumer_stats[ident]["count"] += 1
283 consumer_stats[ident]["last_at"] = time.time()
284
TCP servers¶
The simulation starts two TCP servers which run in separate child processes and each is assigned to one of the consumers. The important part is given below.
67
68 async def handle_echo(reader, writer):
69 data = await reader.read(MESSAGE_SIZE)
70 delay_amount = rand()
71 await asyncio.sleep(delay_amount)
72 """Imitate a time consuming process by delay."""
73 writer.write(data)
74 await writer.drain()
75 writer.close()
76 await writer.wait_closed()
77
It imitates doing a time consuming work by sleeping. The duration of sleep is assumed to be a random number with an adjustable mean value. The TCP servers can be made imbalanced by purposedly increasing the the average value of time delay for one of them.
Controllers¶
288
289 ci = [0.0, 0.0]
290 """Integrator states"""
291 Kp = 1e-2 if not K_PI else K_PI[0]
292 """Propotional gain"""
293 Ki = 1e-4 if not K_PI else K_PI[1]
294 """Integrator gain"""
295 Zi = 1e-2
296 """Integrator damping"""
297 count = [0, 0]
298 """Total number of times the transitions t13 and t23 fire."""
299
300 async def controller(place):
301 nonlocal ci
302 if not CONTROLLER_ENABLED:
303 """This happens when controller is chosen 'none'"""
304 return True
305 index = int(place._name[1:]) - 1
306 """Get branch index."""
307 sensor = sensors[index]
308 value = await sensor.get()
309 """Receive a notification from the consumer."""
310 if CONTROLLER_TYPE == "C2":
311 """This happens when controller is chosen 'C2'"""
312 count[index] += 1
313 err = count[index] - count[1 - index]
314 """Calculate the difference between branches"""
315 sleep_amount = Kp * err + ci[index]
316 ci[index] = (1.0 - Zi) * ci[index] + Ki * err
317 """PI controller"""
318 if abs(sleep_amount) > 1e4:
319 """This should never happen."""
320 print("!!!", sleep_amount, "!!!")
321 ci[index] = 0.0
322 await net.sleep(sleep_amount)
323 """Give a push to the other branch when it is slower."""
324 return True
325
326 return value > 0 # This is the case when controller is 'C1'.
327
The important lines are
value = await sensor.get()
"""Receive a notification from the consumer."""
The controller places \(k_i\) receive updates from consumers and operate accordingly.
none¶
When there is no control rule in work, the token labeled by ‘○’ loops through \(p_{i1}\) and \(k_i\) without any delay. The task loop of \(p_1\) receives a token from \(t_0\) at each loop and checks output arcs for availability. It always redirects the tokens to \(t_{11}\) because its always enabled when a new token arrives. At the end, all requests are redirected to the consumer \(e_1\).
C1¶
This control rule helps balancing TCP servers, because it waits for a notification from the consumer which informs that last request to the TCP is replied. So, it disables its own branch while waiting and lets \(p_1\) redirect the new token to the other branch.
C2¶
This one implements a PI control based approach. It aims to make the number of requests processed by both TCP servers nearly equal. It keeps track of the number of firings of transitions \(t_{13}\) and \(t_{23}\) and tries to make their difference as minimum as possible.
The measured metric is the number of firings and the control input is the sleep function. It delays the branch’s operation if it is going faster than the other branch.
The advantage of using the number of firings of \(t_{i3}\) as a measure instead of the number of tokens processed by the consumers is such that control rule is not effected by the random processing time of the TCP servers. It measures a partially deterministic metric. On the other hand, using the sleep function as the control input introduces an additional delay which limits the total number of processed requests.
Results¶
It is assumed that, the processing time of servers are modeled by an exponential random variable with an average processing delay of 0.01 seconds (100Hz). Each simulation takes nearly 3 seconds.
The simulations are run for all controller types and several token producing rates from 25Hz to 750Hz.
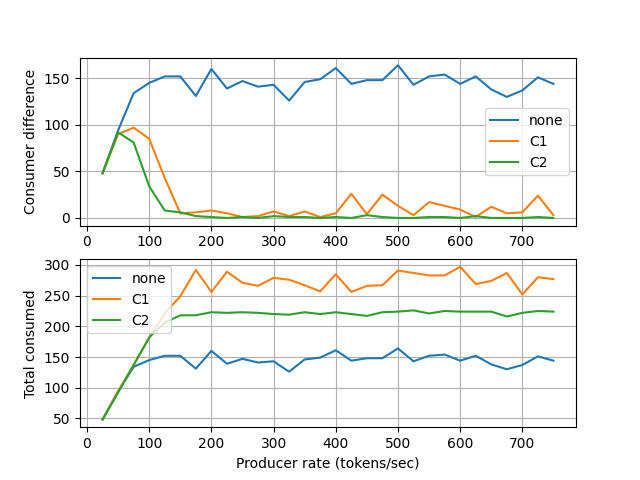
The x axis shows the token producing frequency. The top plot shows the difference between number of tokens consumed by \(e_1\) and \(e_2\) at each simulation. The bottom plot shows the total number of tokens consumed at each simulation.¶
Comments:
At 25Hz producer rate, consumers process the requests faster than token producing rate so 1st branch is always available for redirecting new requests for all control rules. There is a big difference between the number of request processed by consumers.
As producer rate gets close to the average processing delay of consumers (100Hz), the gap between consumed requests goes to zero.
C2 is more successful to balance the number of request processed by consumers, at the expense of an additional delay in the control loop as explained in Section C2.
C1 achieves the best total number of processed requests score and can balance the consumer work loads.
When there is no control rule is present, all requests are piled up in the first consumer’s (\(p_{12}\)) input buffer. It produces the worst scenario among others.
P-controller¶
In this case, the integrator gain Ki is chosen as zero instead of the default
value 1e-4, meaning that only proportional gain is active. The plot below shows the results for
this case.
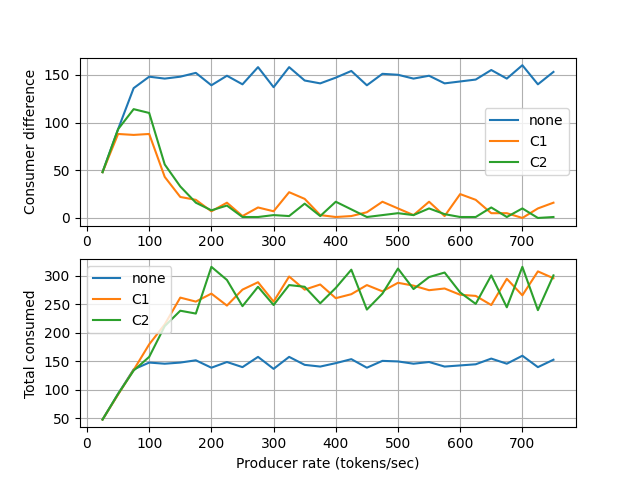
The results when integrator is disabled.¶
Comments:
It shows the effectiveness of PI-controller scheme. Because, the controller of a branch (\(k_i\)) tracks the operation of the opposite branch much closely when integrator action is active.
Reproduce¶
sudo apt install python3-venv
python3 -m venv venv
source venv/bin/activate
make build
make build=pi_controller
make clean=pi_controller
make run=pi_controller
make results=pi_controller
make docs
Usage¶
Submodules¶
src.pi_controller.main module¶
- src.pi_controller.main.USAGE()¶
Arguments:
- -T <time (sec)>
total simulation time in seconds (\(T\))
Default: 10
- -c <none|C1|C2>
controller type
Default: C1
- -o <filename>
output file name to write results. If empty, prints to stdout.
- -L <option>
- change in server load by time
e.g. 0.2,2;0.8,0.33;
Means load on 2nd consumer will be two times more than 1st consumer after time instant \(0.2T\) until time instant \(0.8T\). Then, its load will be 1/3 of 1st consumer’s load until the end of simulation.
Default: “0,1;”
- -p <rate (Hz)>
new token output rate of the producer at each second
Default: 10
- -H hostname
Default: 127.0.0.1
- -P ports
port1,port2
Default: 8888,8889
- -r <option>
- random number generator params
e.g. exponential,0.1
Meaning consumation time of a token takes a random amount of time with an exponential distrbution having an average of 0.1 seconds.
Default: exponential,0.5
- -G
if provided, the script generates PT net graph and exits
- -K
- comman separated PI controller gain values
e.g. 1e-1,1e-2
Default: 1e-2,1e-4
Example
python src/pi_controller/main.py -T 8.5 -r exponential,0.05 -p 100 -c none
- src.pi_controller.main.main(argv)¶
Main entry point of the simulation.
- Parameters:
argv – Command line arguments
- Returns:
Exit status
- src.pi_controller.main.server_main(args, cond)¶
src.pi_controller.results module¶
- src.pi_controller.results.load_result(fn)¶
- src.pi_controller.results.main(argv)¶
- src.pi_controller.results.plot_results(results, output_file='')¶